开yun体育网那便是每秒25万好意思元-开云平台网站皇马赞助商| 开云平台官方ac米兰赞助商 最新官网入口

Key Points
从快念念到慢想:缠绵范式变了,芯片的架构也需要改变;
黄仁勋给出了每两年更换一代架构的芯片计谋,但他更蹙迫的计谋是对于AI的;
AMD争夺终局,英伟达押注云霄;
AI芯片自己的护城河其实莫得那么深,尤其推理芯片。
「一个Hopper芯片不错为每个用户每秒产生精炼100个token,一个兆瓦级数据中心每秒不错产生10万个token。」黄仁勋说,如果进行超等批量处理,那么一个AI工场每秒不错产生的token量不错达到精炼250万个。
「ChatGPT的成本精炼是每百万个token 10好意思元,250万乘以10,那便是每秒25万好意思元。」他络续说,一年精炼有3000万秒,乘起来便是上万亿,「这便是兆瓦级数据中心的营收,这便是您的方针。」
当地时候3月18日,黄仁勋在由英伟达举办的年度GTC(GPU Technology Conference)大会上进行了一场长达两个半小时的演讲。和此前历次在GTC、台北Computex电脑节以及不久前举办的CES大会上的发言不同,黄仁勋在这次GTC大会上作念的最多的事情之一便是算账。

黄仁勋说,DeepSeek火了之后,4大云厂商反而买了更多英伟达芯片,而不是更少。
本年1月底DeepSeek大火之后,由于西宾和推理成本的数目级式下降,阛阓有声息合计阛阓不再需要那么多英伟达芯片了,英伟达股价因此从153好意思元/股的高点沿途着落到104好意思元/股。省略出于试图扭转阛阓对英伟达畴昔观念的起因,3月18日的演讲中,黄仁勋铆足了劲构建和倾销他的「token经济学」。
「旧年,简直全天下王人错了。」他断言说,「AI的缠绵需求事实上是加快的,其范畴化定律(scaling law)具有强劲韧性。」
凭据他的算法,「模子推理需要的算力花消比咱们当下以为的还要多100倍。」
英伟达也曾是刻下民众最大的AI芯片公司。凭据Jon Peddie Research数据,扬弃2024年三季度,英伟达在民众AI芯片阛阓份额高达90%;与此同期,以AI芯片为主的数据中心业务亦然英伟达营收和利润的最大孝敬者,占比高达88%。
这家公司还能若何增长?黄仁勋的每次公开演讲王人在回复这个问题,这次也不例外,但外界买不买账是另外一趟事。
从快念念到慢想:缠绵范式变了,芯片的架构也需要改变
发布会一运转,黄仁勋就点出了旧年DeepSeek推出后业界对于「AI缠绵需求行将断崖式下滑」的判断不仅是错的,而且错得离谱。他给出的根由不是杰文斯悖论中提到的「驱逐提高反而令资源花消激增」,而是缠绵范式的调遣自己带来的——大模子正在从GPT那样的直观式「快念念考」模式,转向OpenAI o1和DeepSeek R1这么通过构建冉冉推导的念念维链进行推理的「慢想」模式。
黄仁勋合计,模子念念考范式的切换,会同期为模子西宾和推理阛阓带来缠绵量上的大幅增长。最初,当大模子公司们意志到将「预西宾」好的基础模子(比如GPT)再使用强化学习方法进行「后西宾」之后,就能得到具有多步念念考才略的推理模子,模子西宾的需求就会再次得到一拨算力增长;其次,也更蹙迫的是,推理模子的多步以致反念念流程,会比平直给出谜底花消更多token——黄仁勋展望这种慢想花消的token量精炼是快念念模式的10倍。
「为了保持模子的反应速率和交互性,幸免用户因恭候其念念考而失去耐烦,咱们刻下还需要缠绵速率提高10倍。」黄仁勋说,如斯一来,token花消量加多10倍,缠绵速率也提高10倍,合缠绵量「搪塞地就能达到百倍」。

黄仁勋说,数据中心AI阛阓会成长到1万亿好意思元的范畴。
黄仁勋称,英伟达在畴昔每一个新缠绵时间到来的拐点时刻王人实时推出了稳当阛阓需求的芯片。2022年ChatGPT大火之年,英伟达推出了AI芯片的第一个系列Hopper系列,2024年,o1推理模子降生之前,英伟达也推出了新的Blackwell系列。相较于Hopper架构,Blackwell系列芯片的架构更得当「推理」——它新增了对FP4(4位浮点运算,数字越高,缠绵精度越高)数据神志的撑持,同期加大了内存。
以2024年3月推出的B200(Blackwell系列的第一款芯片)为例,它首度撑持FP4精度的缠绵。低精度缠绵对于刻下流行的MoE(夹杂大家模子)架构是必要的,成心于裁减西宾和推理的成本与驱逐。DeepSeek的R1模子便是一种MoE架构,而且继承以FP8为主的低缠绵精度西宾和推理。因为推理时只需要调用悉数这个词模子中的一丝「大家」,而毋庸动用悉数这个词模子的悉数参数,且只需要进行8位浮点运算,不像此前主流模子那样动辄需要缠绵到FP16或FP32的精度,DeepSeek R1能以精炼只须OpenAI o1模子3%的价钱提供推理劳动。
GPU中内存的大小对非推理模子影响不大,但对推理模子至关蹙迫。推理模子的多步推理意味着更大缓存,如果缓存过多,模子推理速率就会下降,这给用户酿成的平直体验便是,模子要花很长一段时候才能想好若何回复问题,而用户耐烦是有限的。为了措置缓存爆炸问题,DeepSeek曾找到一种对缓存数据进行纠合压缩的方法,从而大大减少推理期间的内存使用。收获于这一篡改,DeepSeek的第二代基础模子V2的生成婉曲量达到了上一代模子(V1)最大生成婉曲量的5.76倍。
虽然,DeepSeek的一系列模子是使用英伟达的最低阶AI芯片A100西宾的,其内存和带宽王人有限(A100内存只须40GB,带宽最高2.5TB/s ),缓存压缩是莫得宗旨的宗旨。2024年推出第一代Blackwell系列芯片B200时,英伟达新增了对FP4缠绵精度的撑持,还将内存空间加多到了192GB,平直通过升级硬件措置这一问题。
3月18日的GTC大会上,英伟达进一步发布了B200芯片的升级版B300,内存从B200的192GB进一步加多到288GB,同期,其FP4缠绵性能也比B200提高了50%。

相较于Hopper系列芯片,Blackwell系列芯片为推理产生的缓存提供了更大内存和带宽。
在B300之后,黄仁勋公布了英伟达在AI芯片标的的悉数这个词道路图。道路图表露,在2022年和2023年推出的基于Hopper架构的系列芯片、2024年和2025年推出基于Blackwell架构系列芯片之后,英伟达还将在2026年和2027年发布Rubin新架构和系列AI芯片,再之后是Feynman架构及相应芯片。Rubin和Feynman分手以天体裁家Vera Rubin和表面物理学家Richard Feynman(费曼)的名字定名。

这意味着,英伟达将每两年更新一代芯片架构。这种更新早就不再单纯为了算力,比如从第一代Hopper芯片到第二代Blackwell芯片,芯片加工继承的王人是4nm工艺,尽管晶体管数目有增多,但芯片的性能增长越来越多来自架构的合感性而非算力自己的堆叠。以H100和B200为例,单片H100上有800亿个晶体管,B200加多到2080亿个,只加多了1.6倍。但性能上,B200的缠绵性能差未几是H100的5倍——这种驱逐更多来自于对束缚进化的算法的适配。
「芯片要措置的不光是缠绵问题,如故I/O(开或关,即与资源分派、通讯探求的问题)问题。」CUDA之父巴克(Ian Buck)曾默示。以越来越多被使用的MoE夹杂大家模子为例,这种架构将模子理解成一群擅长不同任务的大家,谁擅长什么,就将相应西宾和推理任务分派给谁。如斯一来,不同人凡间的并行缠绵和通讯就变得蹙迫。为了找出访佛GPT-4这么的MoE模子西宾时最合适的并行设立,英伟达曾进行过大批执行,以探索构建硬件和切割模子的正确组合。
AMD争夺终局,英伟达押注云霄
从Blackwell架构运转,英伟达的芯片业务就越来越偏向于云霄AI缠绵了。这种倾向一方面体刻下英伟达对于自家芯片适配模子算法迭代的实时性追求上:2024年3月发布Blackwell系列的第一款芯片B200时,推理模子尚未问世,OpenAI直到当年9月才推出其首款推理模子o1。B300的发布意味着英伟达只花了几个月时候,就准备好了一款更好适配新类型模子的芯片。如果凭据好意思国半导体究诘机构SemiAnalysis的报说念,B300行将推出的音讯早在旧年12月就出现了,意味着市面上首款推理模子o1出现3个月后,英伟达的适配芯片就差未几就绪。
另一方面,英伟达对于云霄AI芯片的侧重也体刻下其对云霄即数据中心业务的嗜好进程上。不论是Hopper如故Blackwell,以及之后的Rubin和Feynman,这一系列芯片王人是为数据中心准备的,只须何处的劳动器才能运行如斯算力范畴的芯片,用以模子西宾或者云霄推理。

数据中心业务成为英伟达最大的获利机器。
而与此同期,AMD正花猖厥气想要霸占的,是每个东说念主不错拿在手里、放在家里桌面的袖珍斥地里的终局AI芯片。就在英伟达GTC大会召开的前一天,AMD在北京召开了「AMD AI PC」为主题的篡改峰会,AMD董事会主席兼CEO苏姿丰躬行站台,扩张公司旗下多个AIPC处理器,包括锐龙AI Max系列、锐龙AI 300系列、锐龙9000HX系列等,秘书搭载这些新品的AIPC将很快面世。空想、华硕、微软、宏碁等PC厂商王人参加了AMD的这次峰会。
云霄数据中心业务对于英伟达的买卖简直越来越蹙迫。扬弃2025年1月26日的2025财年,英伟达已矣总营收1305亿好意思元,其中以AI芯片为主要居品的数据中心业务营收达到1152亿好意思元,范畴差未几是游戏及AIPC为代表的终局业务的10倍,在总营收中占比高达88%。
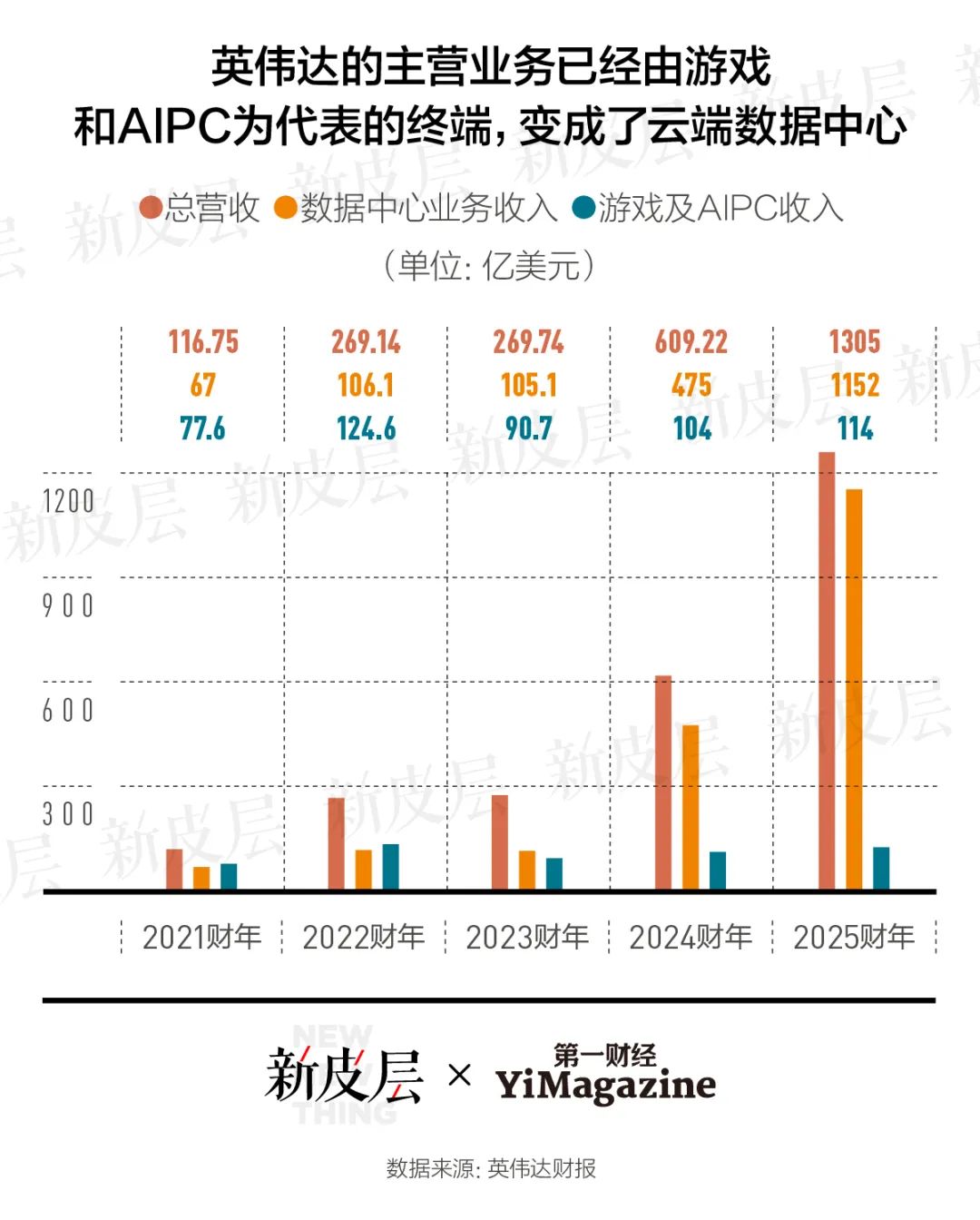
云霄业务的强劲增势从扬弃2023年1月的2023财年就运转了。2022财年,英伟达收入的主要孝敬者如故游戏机中的GPU,2023财年,云霄与终局的力量就回转了。到2025财年,这种力量各异积聚到了10倍的高度。
不成说英伟达也曾澌灭了终局阛阓,「GPU云有其自身的条目,但令我额外欢叫的一个范畴是角落缠绵。」黄仁勋在演讲中说,不外对于把东说念主工智能部署到终局,他给出的例子主如果汽车和机器东说念主,而不是PC。
对于PC,英伟达给出的决策是超等缠绵机——DGX,一个完备的个东说念主电脑,有DGX Spark和DGX Station两个技俩。其中DGX Station搭载了英伟达本日发布的B300芯片的组合版GB300,大小和Mac Mini相配,售价3000好意思元。英伟达称,这两款缠绵机将于本年晚些时候从惠普、戴尔、空想、华硕等OEM厂商何处出货,面向议论东说念主员、数据科学家、AI开发者和学生。这款超等缠绵机最早在本年1月的CES上出现过,其时英伟达给它的定位是「民众最小的个东说念主AI超等缠绵机」。

与AMD力求将其AI芯片植入各大电脑品牌厂商的PC斥地中不同,英伟达的这个缠绵机项目看起来不像是为与既有终局斥地厂商达成和洽、用英伟达芯片「赋能」它们而推出的,反而更像是为了挑战以致颠覆它们而存在。「咱们需要新一代的缠绵机。」黄仁勋说。
AI计谋先于芯片计谋,但老本阛阓并没那么买账
整场演讲中,黄仁勋所评论的东西让他看起来不像仅仅一家芯片公司的CEO,而更像是悉数这个词东说念主工智能行业的意见魁首:不啻讲求芯片自己的架构演化,更想要引颈东说念主工智能行业的畴昔标的。
旧年的GTC上,黄仁勋就表露了他要对产业上游——模子层以致期骗层的深嗜。其时,他发布了不错闪开发者基于英伟达芯片开发和部署生成式AI助手的NIM(NVIDIA Inference Microservice)劳动,以及不错充任机器东说念主大脑的基础模子Project GR00T。

本年的GTC大会上,他进一步发布了GR00T N1模子,堪称民众首个开源的、可定制的东说念主形机器东说念主基础模子,继承分层架构,包括一个动作模子和一个决策模子。能够处理持取、移动物体以及在双臂之间转机物品等通俗动作,也能引申需要多步推理的复杂任务。演讲会场,黄仁勋还让搭载了GR00T N1模子的机器东说念主——Blue(星球大战中的机器东说念主扮装)出来走了几圈,并跟它互动了几句。

加载了GR00T N1模子的机器东说念主——Blue。
此外,他还秘书英伟达在与DeepMind、迪士尼和洽议论一个物理引擎,名为Newton(牛顿),方针是让机器东说念主像东说念主类那样勾通摩擦力、惯性、因果关系和物体恒存性。这一模子畴昔也要开源。
这些在模子层的开源投资,意味着英伟达并非真实想要把业务拓展到软件层,而是想要竖立一种生态。就像CUDA之于英伟达的GPU一样,一个够水准的基础模子(比如DeepSeek)所能构建的软件生态,对于英伟达想要拓展的机器东说念主芯片、自动驾驶芯片,雷同蹙迫。在算法尚未敛迹阶段,这是让其芯片能够实时适配算法演进最有用的形式。

与DeepMind、迪士尼和洽议论一个物理引擎Newton(牛顿)。
黄仁勋大谈了AI,不外,他的投资者们更真贵的如故芯片。整场大会中,黄仁勋一次也莫得提到自动驾驶芯片Thor。这款芯片早在2022秋季的GTC大会上就发布了,撑持L4级自动驾驶,蓝本规画2024年年中量产,迄今仍未有进一步音讯。小鹏、蔚来等汽车厂商等不足Thor的量产而在最新款车型中继承了自研芯片。
除了云霄数据中心,英伟达在游戏与AIPC、自动驾驶方面的事迹也曾多年不增长了。
3月18日的演讲运转前,英伟达股价着落近1%,演讲驱逐后,跌幅扩大至3.4%。
AI芯片自己的护城河其实莫得那么深,尤其推理芯片
不少中国芯片厂商也曾看到了AI推理带来的缠绵范式变化和阛阓契机,并已推出居品分食相应的数据中心阛阓。
一位国产芯片行业从业者告诉第一财经「新皮层」,2017年,英伟达在芯片瞎想中推出tensor core,从科学缠绵、图形渲染等标的冉冉转向AI的旅途考证到手后,中国的AI芯片厂商们就随之竖立了。2018年9月,阿里巴巴竖立了孤独的芯片公司平头哥。2019年,华为秘书推出头向AI阛阓的昇腾系列芯片。燧原科技、壁仞科技、摩尔线程等初创公司紧随着就竖立了。它们研发的GPU居品主要面向AI阛阓。芯片的研发周期每每为2至3年。2024年DeepSeek推出时,这些公司基本王人已领有锻真金不怕火的AI芯片居品。DeepSeek模子发布后,赓续有国产芯片厂商声称自研芯片适配DeepSeek模子。

这些国产GPU公司的AI芯片暂时还难以同英伟达的Hopper、Blackwell等居品同台竞争,但出于芯片禁运等地缘政事风险,不少国产AI芯片也在从中国阛阓得到订单。「以前可能是美艳性地签署计谋和洽条约,刻下产业高下贱和洽愈加细致,有的芯片公司职工运转住在客户公司里连夜调试,提高芯片性能。」上述国产芯片从业者对「新皮层」说,在DeepSeek出现之后,国内产业高下贱运转信得过看到了两边的价值。
一位英伟达的中国区代理商默示,本年是她第二次参加GTC大会。黄仁勋的演讲上昼十点运转,她列队近2小时,卡点在9:50运气进场——跳跃时候即使有票也无法参预了。这位代理商对「新皮层」称,与本年的演讲比拟,旧年黄仁勋演讲时提到的时期、居品和悉数这个词CUDA生态理念让她愈加颠簸。她合计,AI推理阛阓「畴昔会出现几分寰宇的情况,英伟达的优先性更高,但中国内地阛阓的特质是期骗饱和细分、需求饱和多,国产芯片厂商很快能知说念客户需要什么,能实时调优得到反馈,比拟好意思国、欧洲,这是中国阛阓的优点。」
CUDA生态当作英伟达的护城河虽然仍然存在,不外它不再是岿然不动。上述英伟达代理商和国产芯片研发者王人对「新皮层」称,华为晟腾也像英伟达那样从芯片底层运转构建了悉数这个词infra软件生态。DeepSeek在2月底一语气一周开源的多项infra软件,既让英伟达的CUDA软件生态更丰富了,也让外界看到英伟达的芯片架构莫得那么难被琢磨了了,CUDA对于芯片与模子开发者之间的绑定关系被消弱。
另一位芯片产业东说念主士对「新皮层」称:「前两年芯片生态的锚点在CUDA上,但刻下的锚点变得更底层(即芯片架构自己),在这个层级,昇腾和英伟达芯片(靠近的挑战)是一样的。」
另外,前述芯片产业东说念主士告诉「新皮层」,在AI西宾场景下开yun体育网,由于需要继承强化学习、夹杂大家架构等形式去调试算法,国产芯片「堆数目」不成措置根底问题,与英伟达的差距可能会拉大。但在AI推理场景下,由于模子算法已固定,硬件性能的不足不错通过加多芯片数目措置,「用双卡以致多卡弥补差距」。
